コラム
2022-01-24
AWS Direct Connectの冗長化の重要性~後編

「AWS Direct Connectの冗長化の重要性~前編」では、AWS Direct Connect(以下、Direct Connect)の基本的な仕組みを概観しつつ、クリティカルなアプリケーションに求められる冗長構成のパターンや、それほどクリティカルでなく、コストを抑えたいときに利用するパターンと、さらにその際の考慮点について紹介しました。後編では、冗長構成のパターンの応用編として、実際にあった障害ケースを踏まえ、アプリケーション、ひいては業務への影響を最小限にするためにはどのような考え方を持つべきなのかを紹介します。
AWSの大規模障害事例
AWSは過去にさまざまな障害が起きています。後述する日本国内でのDirect Connectの障害事例[※1]以外にも、同じ東京リージョンで2019年にデータセンターの冷却設備のトラブルで一部のサービスのパフォーマンス劣化が発生[※2]しています。海外に目を向けても、アメリカのリージョンで2020年11月にストリーミングデータをリアルタイムで収集・分析するKinesisに対する機能追加時に数時間のサービス影響が発生[※3]するなど、大規模な障害が発生しており、AWSも決して完全無欠のサービスではないことがわかります。
2021年9月に日本国内で起きた障害事例
2021年の9月に、約6時間にわたって東京リージョン内全域のAZ間の接続を司るネットワークデバイスに問題が発生し、特定のAZだけではなく東京リージョンすべてのDirect Connect を経由した接続に影響が発生してしまいました。[※4]
では、どのようにしたらDirect Connectにおける障害の影響を回避、もしくは軽減できるのでしょうか。障害は必ず起こるものなので、100%の回避は難しいのが実情ですが、ある程度の回避もしくは軽減を図ることはできますので、考え方と方法を紹介します。
Direct Connectの障害対応策
1. AWSにおける障害対策の基本:Design for Failure(障害を想定した設計)
AWSにおいては、単に障害を回避するように設計するのではなく、万が一の障害発生時の復旧や縮退時の運用など、障害発生時から復旧までの運用設計も非常に重要です。障害発生時に手動で切り替えを行うのではなく、Amazon CloudWatchなどのサービスを使い障害を検知し自動で復旧できる仕組みや、障害が発生しても問題なく運用を続けることができる仕組みを設計の段階から志向します。AWSの提唱しているベストプラクティス集である「AWS Well-Architected フレームワーク」の中でも、「運用上の優秀性」「信頼性」のそれぞれの項目の中にて記述されています[※5]。
2. 複数のロケーションにDirect Connectで接続
AWSに限った話ではありませんが、障害対策の基本は単一障害点を作らず、構成要素を分散させることです。Direct Connectの観点で考えてみると、リージョン内でのDirect Connectロケーションを分散させる(東京リージョンであればCC1とTY2のそれぞれのロケーションから接続する)方法があり、さらに万全を期すにはリージョンを東西に分散する方法があります。
一般的なオンプレミスの災害対策でも、東京と大阪にメインサイトとバックアップサイトを分けて設置することが多いため、この手法は有効です。
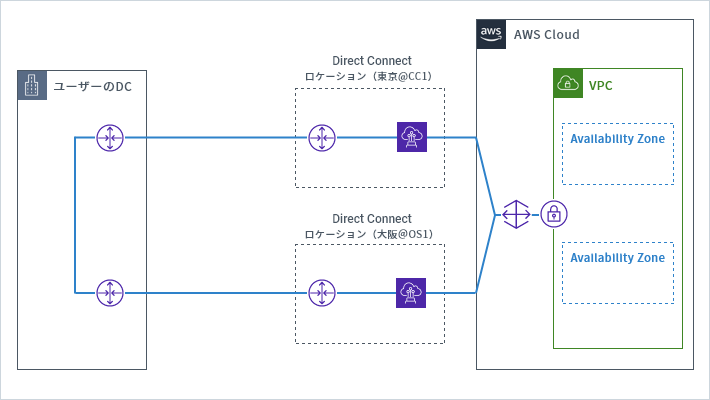
こちらは「AWS Direct Connectの冗長化の重要性~前編」でも、各ロケーション内のDirect Connectを冗長化するケースとして紹介しました。
3. 片系をSite to Site VPNとする
こちらもAWSに限った話ではありませんが、対象への接続をすべて同じ経路・同じ技術を使うのではなく、異なる技術を利用する方法があります。オンプレミスの場合でも、重要なデータセンターとの通信は通信経路を分離し、利用するキャリアを分けるように、AWSにおいても片系をVPNで用意する方法があります。
ただし、開発環境などのコストがかけられない環境向けの手法として有効ですが、メイン系統をDirect Connect、サブ系統をVPN接続とすることはあくまでも障害時の回避策として考えることをお勧めします。VPNのメリット・デメリットについては「専用線とVPNの違いは?セキュリティや品質、使い分け方を比較」で解説しています。
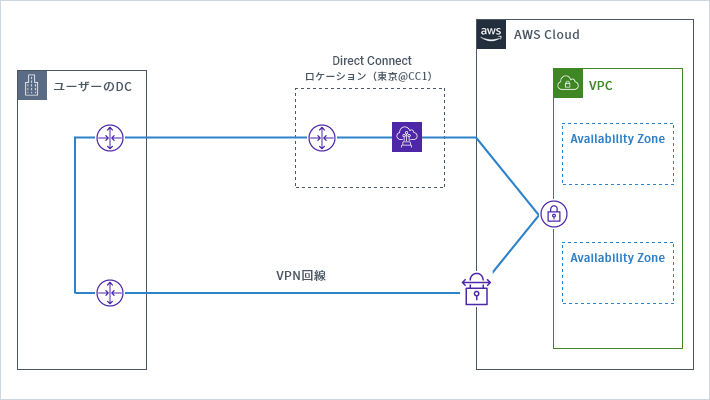
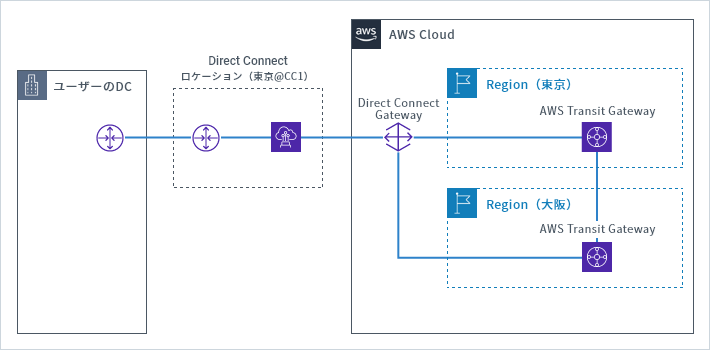
4. リージョン間接続を行う(Direct Connect GatewayとAWS Transit Gatewayを利用)
AWSには、複数のAmazon Virtual Private Cloud(Amazon VPC)をまとめて接続することができるDirect Connect Gatewayというサービスと、複数のAmazon VPC や複数のオンプレミス拠点をハブのように束ねて接続することが可能なAWS Transit Gatewayを併用することで、各リージョン間をピアリングする構成が可能です。これを東京と大阪それぞれに準備することで通常時は東京リージョンAWS Transit Gatewayを利用し、万が一の迂回時は大阪リージョンAWS Transit Gatewayへの経路を利用する、またはその逆の構成で運用することが可能です。
運用における注意点
ここまで、Direct Connectにおける障害の対策を具体的な実装例も交えて紹介しました。しかし、「障害対策・災害対策は作って終わり」というものではなく、日々の運用の中での注意点があります。こちらも、AWSに限らず障害対策・災害対策全般にわたって通じる話であり、そうであるがゆえに重要な考え方です。
切り替え手段は自動と手動を準備
AWSがCloudWatchなどのサービスによる検知や復旧の自動化を推奨していることは、前項のWell-Architected フレームワークで述べましたが、本当に重要なシステムの場合は、その自動化の仕組みが機能しないことが起こりうるということも考慮する必要があります。AWSを利用した自動化の仕組みは、AWSのマネージドサービスを利用して構築されているため、単一AZ障害ならまだしも当該全リージョンで障害が発生してしまい、かつマルチリージョンの切り替えも作動しない可能性さえあります。そのため、有事に備えて、手動での切り替え手順を検討しておくことも必要です。また、オンプレミスの世界でも起きていることですが、対応が複雑になる障害の要因の一つに、中途半端な故障(例えば、完全に機能停止せずに停止と復旧を繰り返すような状況)のケースがあるため、不安定な状態も考慮に入れておく必要があります。
定期的なレビューと障害・災害対策訓練を推奨
上述のとおり、障害・災害対策手順は定期的なレビューと最低年1回程度の訓練が必要です。AWS Direct Connectには、フェイルオーバーテスト機能が用意されており、ユーザー側でルーターに疑似障害を発生させて挙動を見るだけではなく、AWS側の障害起因での切り替え試験を再現することができます。これによって、実環境でのテストで実効性を確認することが可能です。
まとめ
「AWS Direct Connectの冗長化の重要性~前編」では、AWS Direct Connectの概要や利用方法、コストについての整理を行い、冗長化構成の主なパターンやその際の考慮点を紹介し、後編の本稿では障害事例を取り上げて、障害対応における考え方や運用における注意点を紹介しました。オンプレミスとの連携や、高速かつリアルタイムなサービスを動かすにはDirect Connectは必要不可欠な存在です。しかし、数少ない人数で情報システムを運用しているなど、自社でDirect Connectを導入することは難しい組織もあるでしょう。その場合は、Direct Connect サービスデリバリーパートナーであるアイテック阪急阪神であればネットワークからAWSに至るまで経験豊かなエンジニアがサポートしますので、ご相談ください。
関連資料をダウンロード
i-TECクラウドコネクトご紹介資料
クラウド専用線接続サービスの紹介資料です。AWS Direct Connect、Azure ExpressRoute、Oracle FastConnect、Google Cloud Interconnectの導入をご検討中の方はこちらの資料をご活用ください。

出典
- [※1][※2][※3] Amazon Web Services「AWSの大規模障害の報告書(英語)」
- [※4] Amazon Web Services「東京リージョン(AP-NORTHEAST-1)で発生したAWS Direct Connectの事象についてのサマリー」
- [※5] Amazon Web Services「AWS Well-Architected」



